
Posez-vous les questions suivantes : pour quelles raisons voulez-vous créer un site internet ? Pour que de potentiels clients et votre audience vous trouvent facilement, et pour vous démarquer de la concurrence ? Comment votre contenu s’affiche-t-il vraiment ? Est-ce que l’intégralité du contenu de votre site est toujours visible ?
Pourquoi avez-vous besoin de trouver toutes les pages de votre site internet ?
Il arrive que des pages contenant des informations importantes ne s’affichent pas. Un tel problème peut avoir un impact négatif sur votre trafic et vous faire perdre des clients.
Dans d’autres cas, certaines pages ne sont consultées que très rarement par des visiteurs ou de potentiels clients, et lorsqu’elles le sont, ceux-ci se retrouvent dans un cul-de-sac et ils ne peuvent accéder à aucune autre page. Tout ce qu’ils peuvent faire, c’est quitter ces pages. De telles pages vous portent autant préjudice que les pages qui ne sont jamais vues car Google remarquera les taux de rebond élevés qui leur sont associés, mettra en doute la crédibilité de votre site, et il sera de moins en moins bien classées.
Comment les utilisateurs voient-ils le contenu de votre site internet ?
Pour que les utilisateurs, les visiteurs ou les clients potentiels puissent voir votre contenu de votre site internet, il faut que celui-ci soit exploré (on appelle ce processus le crawling) et indexé fréquemment. Que sont le crawling et l'indexation ?

Que sont le crawling et l'indexation ?
Pour pouvoir montrer votre contenu aux utilisateurs/visiteurs/potentiels clients, Google doit tout d’abord comprendre que le contenu de votre site existe, et ceci se fait par le biais du crawling (c’est-à-dire l'exploration d’un site internet). Les moteurs de recherche examinent le site internet pour trouver du nouveau contenu puis l'ajoutent à leur base de données du contenu déjà existant.
Qu'est-ce qui rend le crawling possible ?
- Les liens
- Les sitemaps
- Les systèmes de gestion de contenu (CMS - Wix, Blogger)
Les liens :
Lorsque vous ajoutez à une page un lien qui amène vers une page existante (par exemple par le biais d’un texte d'ancrage), les moteurs de recherche ou les bots suivent la nouvelle page et l’ajoutent à la « base de données » de Google pour référence ultérieure.
Les sitemaps :
Les sitemaps sont également connus sous le nom de sitemaps XML. Ici, c’est le propriétaire du site internet qui soumet la liste de toutes ses pages au moteur de recherche. Le webmaster peut également inclure des détails comme la date de dernière modification. Les pages ainsi soumises sont par la suite explorées puis ajoutées à la « base de données ». Ceci ne se fait cependant pas en temps réel : en effet, l’exploration de vos nouvelles pages (ou de votre nouveau contenu), ne se fera pas dès leur soumission au sitemap, et peut être lancée plusieurs jours, voire plusieurs semaines plus tard.
La plupart des sites qui utilisent un système de gestion de contenu (CMS) les génèrent automatiquement, ce qui constitue un raccourci. Si le site a été créé de toutes pièces, le sitemap n'est pas généré automatiquement.
CMS :
Si votre site internet est alimenté par un CMS (comme Blogger ou Wix), l'hébergeur (dans ce cas, le CMS) peut « informer les moteurs de recherche qu’ils peuvent explorer de nouvelles pages ou un nouveau contenu sur le site internet ».
Voici quelques éléments qui peuvent vous aider dans cette démarche :
- Ajouter le plan du site à WordPress
- Visualiser le plan du site
- Où se trouve le plan du site sur Wix ?
- Le plan du site pour Shopify
Qu'est-ce que l'indexation ?
Pour expliquer simplement, l'indexation désigne l’ajout de pages et de contenu explorés dans la « base de données » de Google (appelée l'index de Google).
Avant que le contenu et les pages ne soient ajoutés à cet index, les moteurs de recherche s'efforcent de comprendre la page et son contenu. Ils cataloguent même des fichiers comme les images ou encore les vidéos.
C'est pourquoi le référencement SEO sur page (les titres de page, les en-têtes et l’utilisation du texte alt, entre autres) est utile aux webmasters. Lorsque ces données sont associées à vos pages, il devient plus facile pour Google de « comprendre » votre contenu, de le cataloguer de manière pertinente, et de l'indexer correctement.
Utiliser robots.txt
Peut-être souhaitez-vous que certaines pages ou certains pans de votre site ne soient pas indexés. Vous devez alors l’indiquer aux moteurs de recherche. Puisque ces indications limitent le nombre de pages à explorer, elles facilitent le processus d’exploration et d'indexation. Pour en savoir plus sur le fichier robots.txt, cliquez ici.

Utiliser « noindex »
Voici une autre option que vous pouvez utiliser si vous ne voulez pas voir apparaître certaines pages dans les résultats de recherche. En savoir plus sur noindex.
Avant d’ajouter des pages à noindex, il vous faudra identifier toutes vos pages afin de nettoyer votre site et de faciliter son exploration et son indexation.
Pour quelles raisons devez-vous retrouver toutes vos pages ?
Qu’est-ce qu’une page orpheline ?
Une page orpheline peut être définie comme une page qui n'a aucun lien avec une quelconque autre page de votre site. Par conséquent, les moteurs de recherche et les visiteurs sont quasiment incapables de les trouver. Si les moteurs de recherche ne peuvent pas trouver une page, elle n’apparaîtra pas dans les résultats de recherche, et les chances que les utilisateurs la découvrent sont minimes.
Qu’est-ce qui provoque les pages orphelines ?
Les pages orphelines peuvent résulter d'une tentative de garder un contenu privé, de fautes de syntaxe, d’erreurs de frappe, d’un contenu redondant ou encore d’un contenu expiré qui n'a pas été lié. Voici d'autres éléments qui peuvent expliquer les pages orphelines :
- des pages de test qui ont été utilisées pour des tests A/B et qui n'ont jamais été désactivées,
- des pages saisonnières (créées à l’occasion de Noël, Thanksgiving, Pâques, …),
- des pages « oubliées » après la migration du site.
Qu'en est-il des pages en impasse ?
Contrairement aux pages orphelines, les pages en impasse sont connectées à d'autres pages du site, mais elles ne sont pas liées à d'autres sites externes. Parmi les exemples de pages en impasse, nous pouvons citer les pages de remerciement, les pages de services sans appel à l'action et les pages « aucun résultat » sur lesquelles les utilisateurs arrivent lorsqu’ils utilisent l'outil de recherche.
Les visiteurs qui arrivent sur ces pages n'ont que deux options : quitter le site ou revenir à la page précédente. Cela signifie que vous perdez un trafic important, en particulier si les pages en question font partie des « pages principales » de votre site internet. Pire encore, les utilisateurs peuvent être frustrés, confus, ou bien se demander ce qui va se passer ensuite.
Si les utilisateurs sont frustrés lorsqu’ils quittent votre site internet, ou confus, ou s’ils ressentent des émotions négatives en général, ils ne reviendront probablement pas, de la même manière que des clients mécontents ne rachèteront probablement jamais les produits d’une marque qui les a déçus.
Qu’est-ce qui cause les pages en impasse ?
Ces pages sont le résultat de pages sans appel à l'action. Par exemple, c’est le cas d’une page de présentation qui mentionne les services offerts par votre entreprise, mais qui ne contient aucun lien vers ces services. Une fois qu’il a compris ce qui motive votre entreprise, les valeurs que vous défendez, la façon dont elle a été fondée et les services que vous proposez, et qu'il est déjà enthousiaste, vous devez expliquer à votre visiteur ce qu'il doit faire ensuite.
Un simple bouton d'appel à l'action « En savoir plus sur nos services » fera l'affaire. Vérifiez que ce bouton, une fois que le visiteur a cliqué dessus, ouvre bien la page appropriée. Vous ne voulez pas que l'utilisateur tombe sur une page 404, car ceci engendrerait également de la frustration.

Que sont les pages mises en cache ?
Les pages mises en caches sont ne sont pas accessibles depuis un menu ou une navigation. Un visiteur peut certes les consulter, notamment via un texte d'ancrage ou des liens entrants, mais elles peuvent être difficiles à trouver.
Les pages qui font partie de la section des catégories sont probablement aussi mises en cache, car elles se trouvent dans le panneau admin. Les moteurs de recherche ne pourront peut-être jamais y accéder, car ils n’ont pas accès aux informations stockées dans les bases de données.
Les pages qui n'ont pas été ajoutées au plan du site peuvent également avoir été mises en cache, même si elles existent tout de même sur le serveur.
Faut-il supprimer toutes les pages mises en cache ?
Pas vraiment. Certaines pages mises en cache sont absolument nécessaires et ne doivent pas être accessibles depuis vos navigations. Parmi ces pages, nous pouvons citer :
Les inscriptions à la newsletter
Vous pouvez avoir une page dédiée à la présentation des avantages qu’il y a à s’inscrire à la newsletter, qui explique la fréquence à laquelle les utilisateurs la recevront, ou encore un graphique montrant la newsletter (ou la précédente). Veillez à inclure le lien d'inscription.
Les pages contenant des informations concernant les utilisateurs
Il est impératif que les pages qui demandent aux utilisateurs de partager des informations soient masquées. Les visiteurs doivent créer un compte avant de pouvoir y accéder. Les inscriptions à la newsletter peuvent également entrer dans cette catégorie.
Comment trouver les pages mises en cache ?
Comme nous l'avons déjà évoqué, vous pouvez trouver des pages cachées en utilisant les mêmes méthodes utilisées pour trouver des pages orphelines ou des pages en impasse. Voici d’autres méthodes :
Utiliser robots.txt
Il est très probable que les pages mises en cache ne soient pas repérables par les moteurs de recherche à cause du fichier robots.txt. Pour accéder au fichier robots.txt d'un site, entrez le [nom du domaine]/robots.txt dans un navigateur et tapez sur « entrer ». Remplacez le « nom du domaine » par le nom de domaine de votre site, puis recherchez les entrées commençant par «disallow» ou «nofollow».
Comment les trouver manuellement ?
Si vous vendez des produits sur votre site internet et que vous pensez que l’une de vos catégories de produits est cachée, vous pouvez la rechercher manuellement. Il vous suffit alors de copier et de coller l’adresse URL d'un autre produit et de la modifier en fonction de ce que vous recherchez. Si vous ne la trouvez pas, c'est que vous aviez raison !
Que faire si vous n’avez absolument aucune idée de quelles pages sont mises en cache ? Si votre site internet est organisé en répertoires, vous pouvez alors ajouter le nom du domaine, ou le nom du dossier, au navigateur du site, et naviguer dans les pages et les sous-répertoires.
Une fois que vous avez trouvé vos pages en cache (notez qu’elles ne doivent pas nécessairement rester en cache, comme nous l’avons expliqué précédemment), vous devez les ajouter à votre sitemap et soumettre une demande d'exploration.
Comment trouver toutes les pages de votre site ?
Il est nécessaire de trouver toutes les pages internet de votre site afin de savoir lesquelles sont en impasse ou orphelines. Voici différentes méthodes qui vous permettront d’y parvenir :
En utilisation votre fichier sitemap
Nous avons déjà parlé des sitemaps. Votre sitemap vous sera utile lorsque vous analyserez toutes vos pages. Si vous n'avez pas de sitemap, vous pouvez utiliser un générateur de sitemap. Il suffit d'entrer le nom de votre domaine et le générateur créera un sitemap.
En utilisant votre CMS
Si votre site est alimenté par un système de gestion de contenu, aussi appelé CMS, comme WordPress, et que votre sitemap ne contient pas tous les liens, vous pouvez obtenir la liste de toutes vos pages internet à partir de ce CMS. Pour ce faire, utilisez un plugin comme Export All URLs.
En utilisant un journal
Il peut s’avérer utile de disposer d’un journal reprenant toutes les pages proposées aux visiteurs. Pour accéder à ce journal, connectez-vous à votre cPanel, puis recherchez le dossier « raw log files ». Vous pouvez également demander à votre hébergeur de le partager avec vous. Vous pourrez alors voir quelles sont les pages de votre site internet les plus fréquemment visitées, celles qui ne sont jamais visitées et celles dont les taux de rebond sont les plus élevés. Les pages avec un taux de rebond élevé ou qui ne sont jamais visitées peuvent être des pages en impasse ou orphelines.
En utilisant Google Analytics
Suivez les étapes suivantes :
Étape 1 : connectez-vous à votre page Analytics
Étape 2 : rendez-vous sur « behavior », puis sur « site content »
Étape 3 : cliquez sur « all pages »
Étape 4 : en bas à droite, choisissez « show rows »
Étape 5 : sélectionnez 500 ou 1000, en fonction du nombre de pages que vous pensez avoir sur votre site
Étape 6 : en haut à droite, choisissez « export »
Étape 7 : puis « exporter en tant que .xlsx » (excel)
Étape 8 : une fois le fichier Excel exporté, choisissez « dataset 1»
Étape 9 : triez par « unique page views »
Étape 10 : supprimez toutes les autres lignes et colonnes, à l'exception de celles qui contiennent vos URLs
Étape 11 : entrez cette formule pour la deuxième colonne : =CONCATENATE("http://domain.com,A1)
Étape 12 : remplacez le nom du domaine par celui de votre site. Faites glisser la formule pour qu'elle s’applique aux autres cellules.
Vous avez maintenant toutes vos URL. Pour les convertir en hyperliens (afin d’accéder à celles-ci d’un simple clic), lisez l'étape 13.
Étape 13 : entrez cette formule dans la troisième ligne : =HYPERLINK(B1)
Faites glisser la formule pour qu'elle s’applique aux autres cellules.
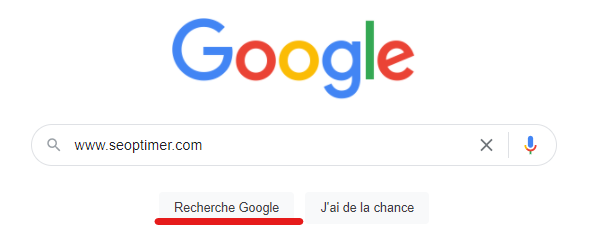
Entrez manuellement votre requête de recherche Google
Vous pouvez aussi entrer le site www.abc.com dans la requête de recherche Google, en remplaçant « abc » par le nom de votre domaine. Les résultats de recherche vous indiqueront toutes les URL que Google a explorées et indexées, et inclura les images, les liens vers les mentions sur d'autres sites, et même les hashtags auxquels votre marque peut être associée.
Vous pouvez copier manuellement chacune d'entre elles puis les coller sur une feuille Excel.
Que faire de la liste d'URLs ?
Vous vous demandez peut-être à présent ce que vous devez faire avec votre liste d'URL. Voici quelques possibilités :
La comparer manuellement aux données du journal
Vous pouvez comparer manuellement votre liste d'URL au journal du CMS pour identifier les pages qui semblent ne pas être consultées, ou qui comptent les taux de rebond les plus élevés. Vous pouvez vérifier les liens entrants et sortants des pages que vous soupçonnez d'être orphelines ou en impasse grâce à un outil comme celui que nous mettons à votre disposition.
Vous pouvez également télécharger votre journal et l’intégralité de vos URL dans un fichier Excel .xlsx. Comparez-les (en les entrant dans deux colonnes, par exemple), puis utilisez l'option « supprimer les doublons » d’Excel. Suivez les instructions étape par étape et, au terme de cette manipulation, il ne vous restera plus que des pages orphelines et en impasse.
Une dernière méthode consiste à copier votre journal et votre liste d'URL dans Google Sheets. La formule : =VLOOKUP(A1, A : B,2,) vous permettra de rechercher les URL qui sont présentes dans votre liste d'URL, mais absentes du journal. Les pages manquantes doivent être considérées comme orphelines. Veillez à ce que les données du journal se trouvent soit dans la première colonne, soit dans la colonne de gauche.
Utiliser les outils d'exploration de sites internet
Une autre option consiste à charger votre liste d'URL dans des outils conçus pour analyser des sites internet, à lancer une analyse, à copier et coller vos URL dans une feuille de calcul, à les analyser individuellement, et à essayer de déterminer lesquelles sont orphelines ou en impasse.
Ces deux options peuvent prendre beaucoup de temps, en particulier si votre site compte de nombreuses pages, n'est-ce pas ?
Que diriez-vous si nous vous proposions un outil qui peut non seulement trouver toutes vos URL, mais qui vous permet également de les filtrer et d'afficher leur statut (pour repérer facilement lesquelles sont en impasse ou orphelines) ?
En d'autres termes, si vous recherchez un moyen rapide pour trouver toutes les pages de votre site, SEOptimer's SEO Crawl Tool est fait pour vous.
L'outil SEO Crawl de SEOptimer
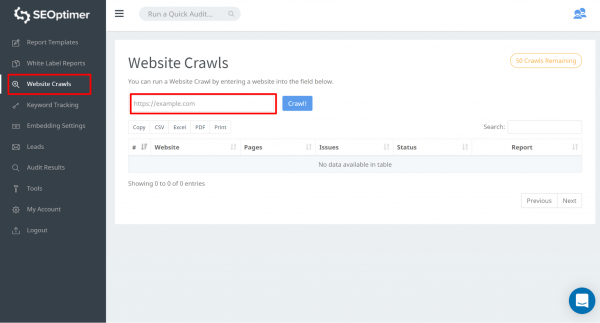
Grâce à cet outil, vous pouvez accéder à toutes les pages de votre site. Pour commencer, allez dans « Website Crawls » et entrez l'URL de votre site. Cliquez sur « Crawl »
Une fois cette exploration achevée, vous pouvez cliquer sur « View Report».
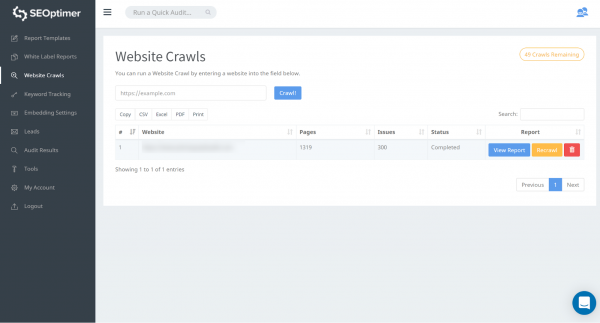
Notre outil détectera toutes les pages de votre site internet dont vous trouverez la liste dans la section « Page found ».
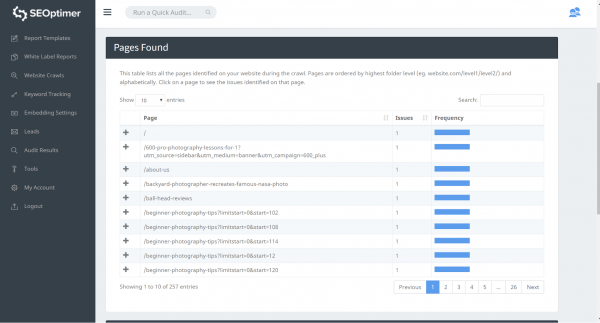
Vous pouvez identifier les problèmes de « 404 Error » sur notre page « Issues found » juste en dessous de la section « Page found »:
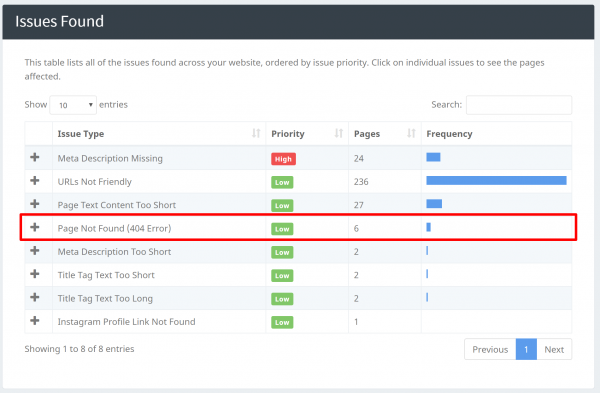
Nos crawlers peuvent identifier d'autres problèmes encore, comme des pages avec des titres manquants, des Meta Descriptions, etc. Une fois que vous avez trouvé toutes vos pages, vous pouvez commencer à filtrer et à travailler sur ces problèmes.
Conclusion
Dans ce guide, nous avons vu comment vous pouvez trouver toutes les pages de votre site internet, et pourquoi il est important de le faire. Nous nous sommes également intéressés à des concepts comme les pages orphelines et les pages en impasse, ainsi qu’aux pages mises en cache. Nous avons expliqué les différences entre chacune d'entre elles et comment les identifier parmi vos URL. C’est le moment idéal pour savoir si vous prenez du retard à cause des pages en cache, des pages orphelines ou en impasse.










